💡 The Idea
Almost a year ago, I had an idea:
To build a free community tool for citizens to mark and report problems in their municipalities.
It has been gestating in my head, until a few weeks ago. Since I’m shifting towards new projects, I had quite some time for myself. That meant reading a lot of books and doing hobby projects, like this one.
In a nutshell, the app does the following:
- A map of Macedonia is shown
- Previously reported problems are displayed, with their location and type
- Upon clicking on a problem, more details are shown (description, vote count, …)
- Users can also tap on a location and report a new problem (they can leave a new description for it)
- All new reports must be verified by an admin
- At the end of each month, a monthly report of problems is generated for each municipality and sent to their email address
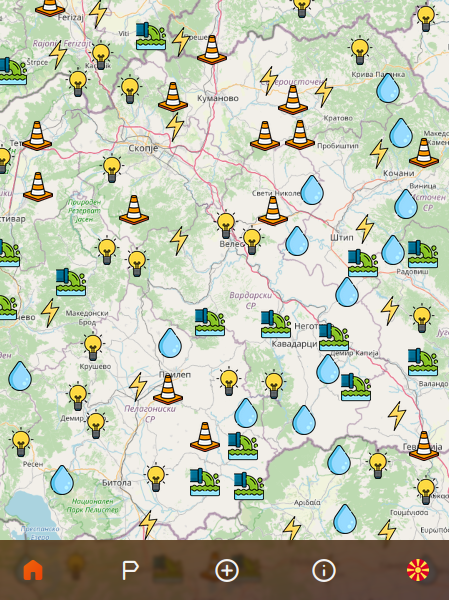 The home screen of the app. (still in development)
The home screen of the app. (still in development)
⚠️ The Problem
All of these are pretty much straightforward, except (2). Users will constantly navigate through the map (zooming and panning), so the server must return the problems fast (in a few milliseconds).
When returning the problems, the server will:
- Take into account the extent users are currently viewing
- Take into account the zoom level they are at
- Make sure there are no conflicting problems (i.e. problems too close to each other)
NOTE: If you like more content like this, please consider subscribing. No spam, I promise :)
✨ The Solution
Let’s first look at the facts.
A single problem is defined like this:
1 | class Problem { |
A single problem will take up to 600 bytes:
| Size | Property |
|---|---|
| 10 bytes | ID (a random 10 char alphanumeric) |
| 4 bytes | ProblemType (an enum) |
| 16 bytes | Point (two doubles) |
| 500 bytes | Comment (250 max char length, but accepting Cyrillic) |
| 4 bytes | Votes (an int) |
| 8 bytes | Time (a long) |
| X bytes | For other operations the JVM might take |
| 542 + X bytes | Total |
0. Assumptions & Limits
I make the following assumptions:
- There will be at most 100,000 reported problems in the system
- There will be at most 500 simultaneous users
- The number of returned problems will be capped to 1,000
- The minimum interval between requests per device will be 250 milliseconds
- Each device will be capped to 10 requests per 5 seconds
- A single user/device can create at most 3 problems per day
Total Problem Storage
With assumption (1), there will be 100,000 problems at the high-end, and each taking up to 600 bytes, the total size of all problems will be:
1 | 100,000 * 600 bytes |
Max Request Load
All users will be able to make 10 requests per 5 seconds, but also at most 4 per second (since the min interval between requests is capped to 250 milliseconds).
From assumption (2), there will be at most 500 simultaneous users. If all of them used the maximum capacity (4 req/sec), then there will be 2,000 req/sec at the most.
This means that the server should return each request in 1/2,000 seconds, or in 500 microseconds!?
Of course not! That’s impossible!
The network transfer overhead is tens of milliseconds, alone. But, we also have to take into account the following:
- The server can process up to 200 requests in parallel
- The server has enough memory to store those 200 requests
- High-consumption users will use up their 5-second capacity in 2.5 seconds, meaning they will not send new requests in the next 2.5 seconds
Given this, the worst-case scenario is:
That in 250 milliseconds, we receive 500 requests.
If we can process 200 simultaneously, then we’ll need 3 rounds to process all of them. If we divide that 250-millisecond interval into 3 intervals, each interval will be 83.33 milliseconds. This is our real limit.
Of course, this includes the network overhead, which can be up to 60 milliseconds.
This means that the time-to-process (TTP) should be less than 23.33 milliseconds!
So far, we have the following numbers:
| Size | Item |
|---|---|
| 600 bytes | Singe Problem Size (SPS) |
| 57.22 MiB | Total Problems Size (TPS) |
| 83.33 millis | Single Request Limit (SRL) |
| 23.33 millis | Time-to-Process (TTP) |
| 0.57 MiB | Max Response Size (MRS) 1,000 * 600 bytes |
| 286.10 MiB | Max Bandwidth Size (MBS) (500 in 250 millis) |
Now, let’s see what are our options.
1. Storing data SQL vs. NoSQL
SQL servers like PostgreSQL, have built-in extensions to handle spacial data (e.g. PostGIS). We can use those extensions to do the filtering of the data.
However, I decided not to use PostGIS for two reasons:
- I don’t know how to write efficient queries, especially ones considering an extent, zoom level, and collision detection
- Given the small TPS size of 57.22 MiB, I believe I can store everything in-memory.
So, I’ll just need a solution for permanent storage. In that case, something like Redis with --appendonly activated should more than suffice.
The “problem creation” endpoint will have only a few hits every few minutes, so it’s not a big deal.
2. Storing data in-memory
Storing data in-memory is pretty straightforward. On startup, fetch everything from the database (Redis in this case), and store it in some collection (Set, List or Map). When new problems are created, just append them to this collection, and store them in the database.
3. Storing only node data in-memory
One thing we can do to save on memory usage is: instead of storing the whole problem in-memory, store only the properties needed for processing.
This means that the comment isn’t really necessary, since it will not be used in the computation.
That’s 500 bytes/problem less!
However, we’ll need another structure for this, let’s call it Node:
1 | class Node { |
With the new structure, our updated TPS will be:
1 | 100,000 * (600 - 500 bytes) |
4. Eliminating out-of-scope nodes
Let’s say we have all our nodes stored in some collection:
1 | Collection<Node> nodes |
For each request, we’ll need to remove all nodes that are not in view on the user’s device.
1 | Collection<Node> getNodes(Point from, Point to); |
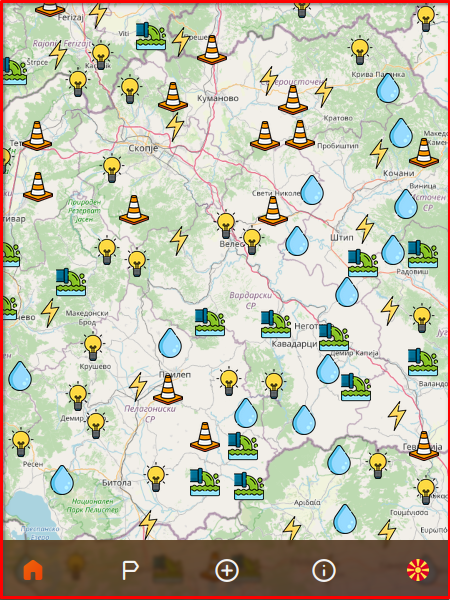 Nodes not visible in the current view, shouldn't be served to the user
Nodes not visible in the current view, shouldn't be served to the user
Given an extent (Point from, Point to), we’ll have to eliminate all points not belonging to the extent:
1 | boolean isInMap(Point from, Point to) { |
This means that the getProblems method will be the following:
1 | Colletion<Node> getNodes(Point from, Point to) { |
However, this will pose two problems:
- The number of problems returned for the full Macedonia map, will be all points
- Close problems, especially on the higher zoom levels, will overlap
5. Limiting Nodes
The fastest way we can limit the number of requests is by using the limit function on the stream. This will take only the first X elements.
From assumption (3), we can limit this to 1,000:
1 | Colletion<Node> getNodes(Point from, Point to) { |
This is in no way a good solution since it’ll limit them non-discriminately, but it’ll suffice for now.
6. Eliminating close neighbors
The second problem we had was: that close neighbors would overlap on the map.
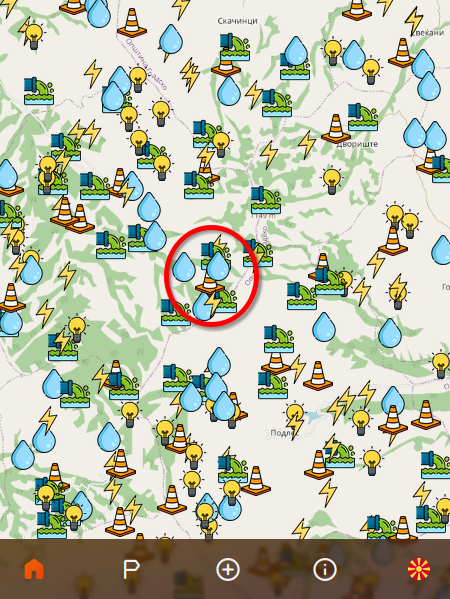 Close neighbors will overlap with their icons on the screen
Close neighbors will overlap with their icons on the screen
To solve this, we’ll need to check each node with the others and see if they’re within a certain distance apart.
This distance will be adjusted depending on the zoom level.
To set some minimum distance between nodes for a certain zoom level, we need to define what a “close neighbor” is.
I have defined it like this:
- Given a device with a viewport of
MxNpixels, - With each map node displayed using a
30x30pixels icon, - The maximum number of nodes in a given row column should be:
max(M, N) / 30 - This will be called the
distanceFactor
Using the distanceFactor, we can calculate the minimum distance between nodes using the following method:
1 | private static double minDistance(Point from, Point to, Double distanceFactor) { |
Essentially what this function computes is the bigger distance on the view port, divided by the max number of possible nodes.
NOTE: We don’t really need the zoomLevel, since we can calculate the distance from the from and to points. The more zoomed-in a user is, the closer the distance between these two points. We can use the zoomLevel for other things like showing all nodes without eliminating close neighbors when it’s at its max.
With this minDistance computed, we can run the following method to eliminate close neighbors:
1 | private static void eliminateCloseNodes(List<Node> nodes, double minDistanceBetweenNodes) { |
This will remove any two nodes that have a distance less than minDistanceBetweenNodes.
7. Ranking nodes by votes and time
In the previous function, you might have noticed another method called compareNodes.
We need this because not all nodes are equal. Some may have more votes than others, some may be older than others. We want to display those with more votes, and those that are older, first.
This means that when two nodes are close neighbors, we will remove the one that has fewer votes, or is newer.
1 | static int compareNodes(Node a, Node b) { |
The updated getNodes method looks like this:
1 | Collection<Node> getNodes(Point from, Point to, double distanceFactor) { |
8. Building map segments and doing (4) and (5) within the segment
One problem we have so far is: eliminateCloseNodes has a O(n^2) complexity (where n is the size of the collection).
Given that there could be up to 100,000 nodes, it’ll be impossible to complete this in a reasonable time (i.e. less than the TTP).
One way we can improve this is, to run the elimination on smaller segments, then merge the results. We can even parallelize this computation.
To do this, we’ll do the following:
- We’ll split the user’s view into 40x40
MapSegments - Each
MapSegmentwill have its own extentPoint from, Point to - We’ll group the node collection into
MapSegments and run theeliminateCloseNodesfor each segment - All remaining nodes will be merged, and a final
eliminateCloseNodeswill be executed to ensure no close neighbors between segments
This will build 1,600 MapSegments, with each on average storing 62.5 nodes (if we have 100,000 nodes).
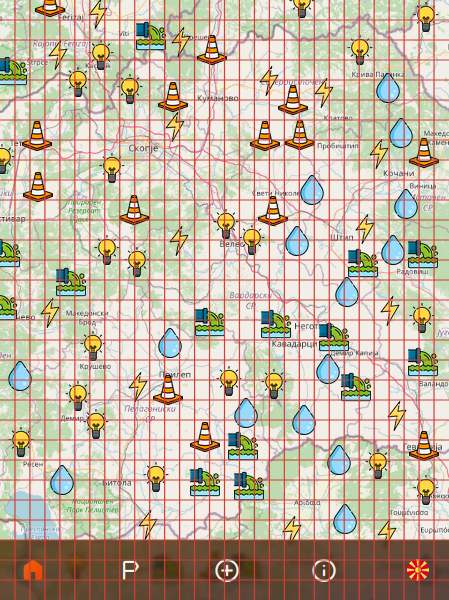 How a segmented view will work. Each square will independently eliminate close neighbors.
How a segmented view will work. Each square will independently eliminate close neighbors.
To achieve this, we can do the following:
1 | Collection<Node> getNodes(Point from, Point to, Double distanceFactor) { |
This will work, and we get the TTP down to less than 50 milliseconds.
But, we still have two problems here:
- We build these
MapSegments on-demand for every request, wasting a lot of time - As the user moves through the map (zooming, panning), different nodes will appear/disappear.
9. Storing nodes in-memory in map segments
To solve the first of these problems, what we can do instead is: Store the nodes in-memory in MapSegments.
So, essentially, do the MapSegment-build on startup and on each newly added Node.
For this, we can define a fixed number of segments. I have decided on 60x60, which means 3,600 segments since they will be for the whole map (zoomed out completely).
On average, a single segment will hold 27.77 nodes. But, since most of these will probably be empty (i.e. some mountainous regions won’t get many reports), we’ll build the MapSegment only when it’s first needed.
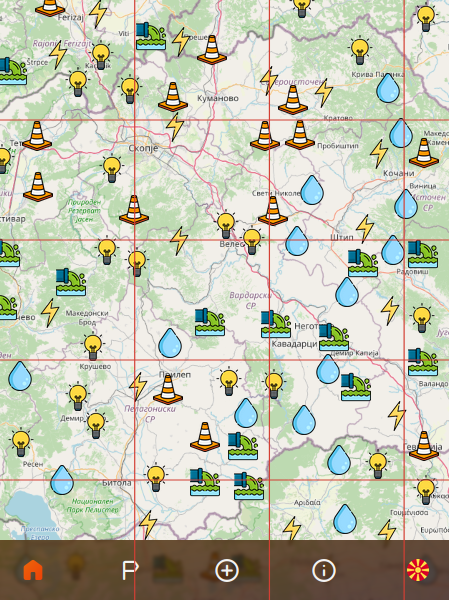 Fixed number of segments means we'll see only a subset of these, some even partially
Fixed number of segments means we'll see only a subset of these, some even partially
10. Sorting nodes by rank in segments
The previous change solved the on-demand bottleneck, but there’s still the problem where zooming in or panning, will remove existing nodes.
What we want is the following:
- At the highest level, the most important nodes are shown
- As we zoom in to a certain area, those that were in the higher zoom levels MUST be present otherwise we might lose a node that we zoomed into.
The reason this happens is because:
- Given two adjacent segments, as we zoom in, more nodes will be taken from each
- Higher-level nodes from segment A might have fewer votes or they can be newer than lower-level nodes in segment B
- Thus as we zoom in, segment B’s lower-level nodes might win over segment A’s higher-level nodes
What this means is:
If a segment’s node has already been shown, the vote/time algorithm shouldn’t matter.
To calculate this, we can add another property called rank. In each MapSegment each node will get its own rank (i.e. sorted index), and as we pull the first X nodes, only those with the highest rank will be taken first.
Later, when we merge the segments, the last call to eliminateCloseNodes will take into account the rank, as well, and so higher-ranked nodes will not be eliminated due to smaller vote count or newer time.
The new compareNodes method will look like this:
1 | static int compareNodes(Node a, Node b) { |
Another opportunity that has shown up here:
We can dynamically limit the number of nodes taken from each segment by calculating how many MapSegments are shown within the sent extent, and dividing 1000 by that number.
1 | nodesPerSegment = Math.max(1000 / numberOfVisibleSegments, 1); |
11. Adding a segment scope
Remember previously we mentioned that we’ll build the MapSegment on-demand? Well when we start, at first there will only be a couple of segments (out of 3,600), since in all others there will be no nodes, hence, no need for a segment to exist.
Here’s the funny thing:
As we zoom or pan the map, the number of visible MapSegments will vary. This means the number of nodesPerSegment will change.
The problem is this: as the number of visibleSegments increases, nodesPerSegment decreases, thus removing certain nodes just by panning.
We don’t want to lose a node as we pan the map!
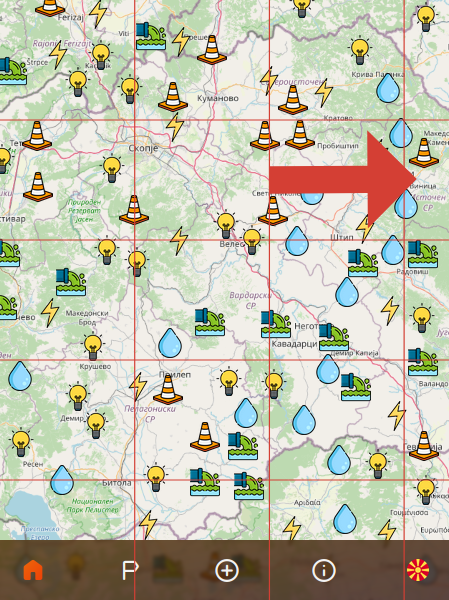 Panning or zooming will remove nodes
Panning or zooming will remove nodes
To solve this problem, instead of calculating how many segments are visible, we’ll create an imaginary “scope” that will tell us how many segments would be visible, if all segments were existent.
To calculate this, we can define a fixed map extent (Point from, Point to), then calculate the width and height of each MapSegment.
Then, given the user’s extent, we can calculate the segment count, using the following formula:
1 | long segmentCount = Math.min( |
This will ensure that regardless of the current view, and the existence of a MapSegemnt, we’ll always get the same amount of segments, even when panning.
This is the final state I ended up with.
Benchmarking this, gave me results with less than 5 milliseconds for TTP, less than 1 millisecond when zooming in. That’s well below the 23.33 milliseconds limit for the TTP.
🚀 Next Steps
I’m sure there are a lot of other things that can be optimized here. Here are a couple.
Scale-out to multiple instances
The easiest way is to scale the number of instances and then load-balance the traffic.
We have to take into account scaling/sharing the storage here, but it should be fairly easy to achieve in this case.
Shard the data
We can also have multiple instances, with each instance only serving certain sub-segments.
Use more optimal structures and/or language
- We can use more primitive types for certain properties.
- We can build a graph with distances, within and between segments.
- We can use a more efficient language (C/C++, Rust, …).
That’s it this one 👋
If you’d like to track the progress of this app and get a notification when it’s launched, please subscribe to my newsletter, below.
I’m always open to suggestions, and improvements. If you want to see the whole code, write me an email.